
A Mathematical Overview of Dimension Reduction in Text Classification
7 Mar 2025
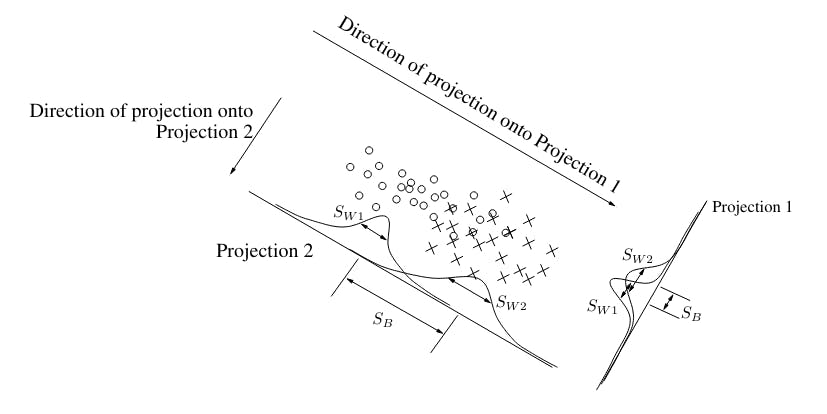
Learn how dimension reduction improves text classification by optimizing feature clustering using scatter matrices.
A Brief Introduction to Statistical Parsing
7 Mar 2025
This intro to statistical parsing explains how probabilistic context-free grammard help decipher sentence structures, a key tool in authorship identification
When Words Won’t Talk, Sentence Structures Spill the Truth
7 Mar 2025
This study explores how statistical parsing of sentence structures enhances authorship attribution, revealing hidden stylistic differences in many cases.
Can AI Tell Jane Austen’s Writing Apart from a Fake?
7 Mar 2025
A stylometric analysis of Sanditon reveals subtle linguistic patterns distinguishing Jane Austen’s original writing from a later continuation by “Another Lady.”
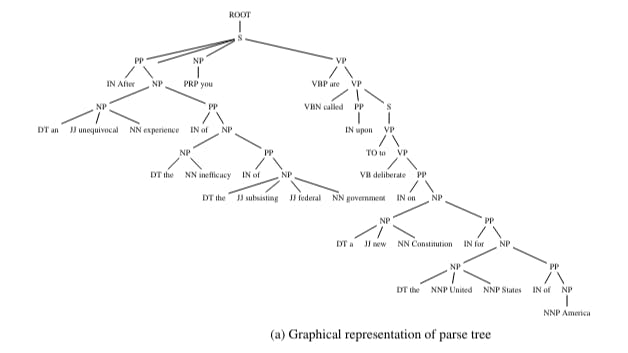
Deep Syntax and Dead Founders: How AI Deciphered The Federalist Papers
7 Mar 2025
This study applies statistical parsing to The Federalist Papers, leveraging syntactic structures to distinguish authorship with high accuracy.
How LLMs Learn to Recognize Different Writing Styles
7 Mar 2025
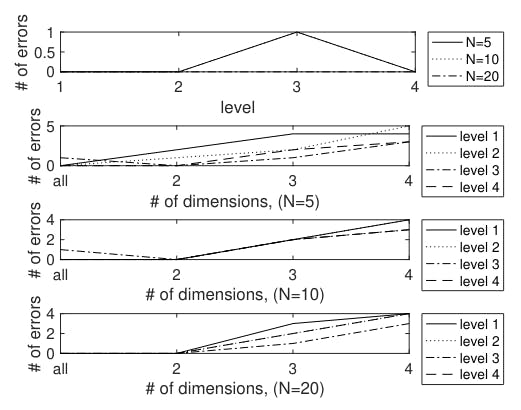
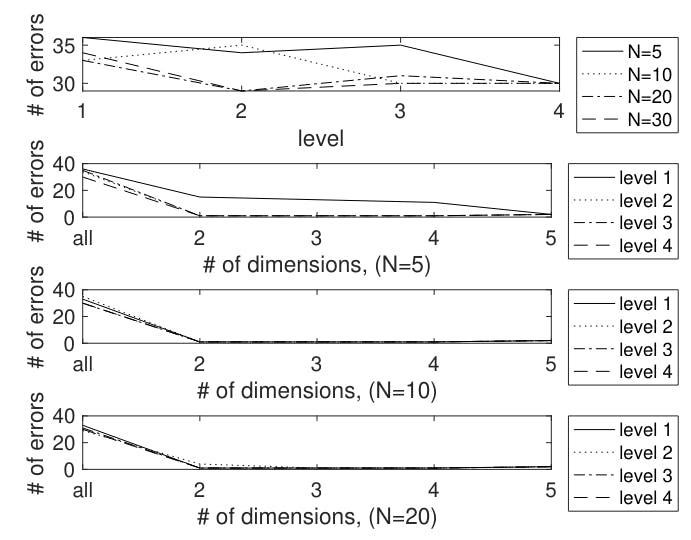
This study explores dimension reduction techniques, optimizing feature vectors to improve authorship classification accuracy in high-dimensional data.
Can Grammar Patterns Unmask a Writer’s Identity?
7 Mar 2025
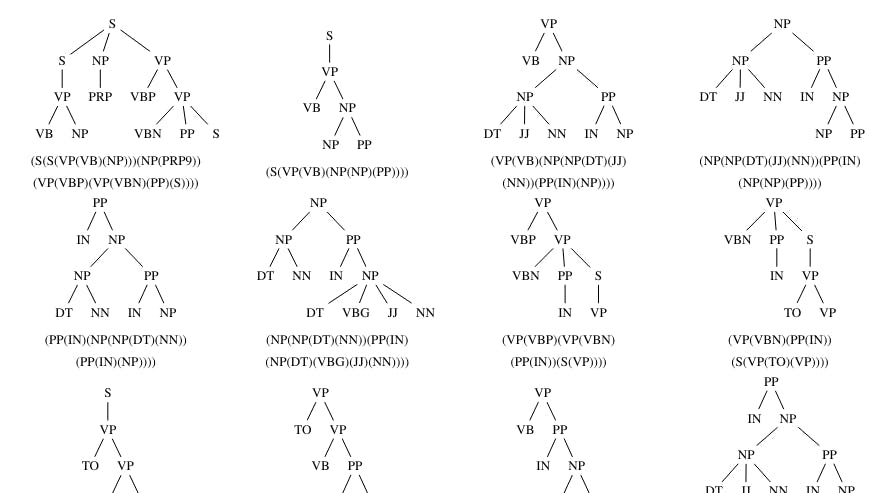
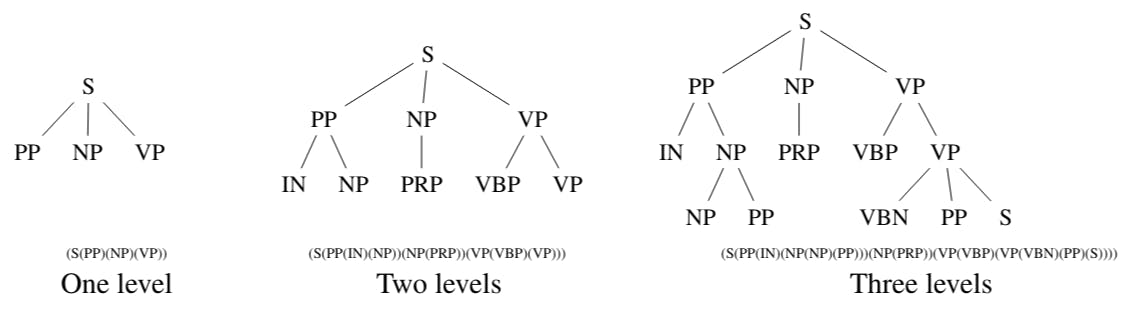
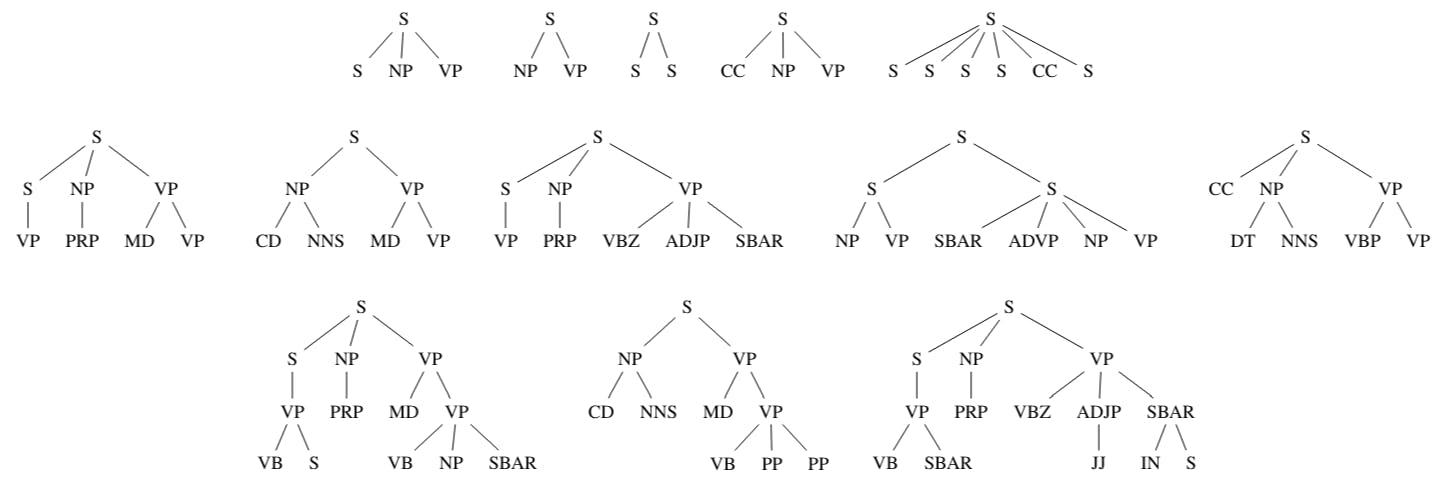
This study explores different parse tree features—subtrees, rooted structures, and POS patterns—to enhance authorship classification accuracy.

Can AI Tell Who Wrote Something Just by Analyzing Grammar?
7 Mar 2025
This study leverages statistical parsing and syntactic structures from the Penn Treebank to refine authorship detection using the Stanford Parser.

Your Writing Has a Fingerprint—And This Cutting Edge AI Model Can Identify It
7 Mar 2025
Using grammatical structures from parsed text, this study explores a new method for detecting authorship, improving accuracy in AI and fake text identification.